8.1 PyTorch入门
这个 notebook 与第8章-部分1讲义配套。重点不是学习很多 PyTorch 语法,而是把 Logistic 回归的数学对象对应到代码:
数据
TensorDataset和DataLoader;参数
nn.Parameter;损失
BCEWithLogitsLoss;梯度下降
zero_grad()、backward()、step()。
import matplotlib.pyplot as plt
import torch
from torch import nn
from torch.utils.data import DataLoader, TensorDataset
torch.manual_seed(42)
plt.rcParams["figure.figsize"] = (5, 3)
plt.rcParams["axes.grid"] = True
print("PyTorch version:", torch.__version__)PyTorch version: 2.8.0
1. Tensor 和参数¶
Tensor 可以先理解成 PyTorch 里的数组。普通数据通常不需要梯度;模型参数需要梯度,所以用 nn.Parameter 表示。
X_demo = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
a_demo = nn.Parameter(torch.zeros(2))
b_demo = nn.Parameter(torch.zeros(()))
logits_demo = X_demo @ a_demo + b_demo
print("X_demo shape:", X_demo.shape)
print("a_demo needs gradient:", a_demo.requires_grad)
print("logits:", logits_demo.detach())X_demo shape: torch.Size([2, 2])
a_demo needs gradient: True
logits: tensor([0., 0.])
2. Dataset 与 DataLoader¶
Dataset 负责保存样本;DataLoader 负责把样本组成 batch。
下面先生成训练集和测试集。训练时只使用训练集;测试集只用来观察模型在新样本上的准确率。
本节使用 full-batch:每个 epoch 用全部训练样本做一次更新。这样更容易看清训练循环。
n_train_per_class = 200
n_test_per_class = 100
noise_rate = 0.10
train_noise_count = int(2 * n_train_per_class * noise_rate)
test_noise_count = int(2 * n_test_per_class * noise_rate)
def make_binary_data(n_per_class, noise_count=0):
class_0 = torch.randn(n_per_class, 2) * 0.7 + torch.tensor([-1.0, -1.0])
class_1 = torch.randn(n_per_class, 2) * 0.7 + torch.tensor([1.0, 1.0])
X = torch.cat([class_0, class_1]) * 3.0
y = torch.cat([torch.zeros(n_per_class), torch.ones(n_per_class)])
if noise_count > 0:
noisy_index = torch.randperm(len(y))[:noise_count]
y[noisy_index] = 1 - y[noisy_index]
shuffle_index = torch.randperm(len(y))
return X[shuffle_index], y[shuffle_index]
# 训练集加入少量“噪声标签
X_train, y_train = make_binary_data(n_train_per_class, noise_count=train_noise_count)
X_test, y_test = make_binary_data(n_test_per_class, noise_count=test_noise_count)
train_data = TensorDataset(X_train, y_train)
test_data = TensorDataset(X_test, y_test)
train_loader = DataLoader(train_data, batch_size=len(train_data), shuffle=False)
test_loader = DataLoader(test_data, batch_size=len(test_data), shuffle=False)
fig, axes = plt.subplots(1, 2, figsize=(8, 3), sharex=True, sharey=True)
axes[0].scatter(X_train[:, 0], X_train[:, 1], c=y_train, s=16, cmap="coolwarm", alpha=0.8)
axes[0].set_title("Training data")
axes[1].scatter(X_test[:, 0], X_test[:, 1], c=y_test, s=16, cmap="coolwarm", alpha=0.8)
axes[1].set_title("Test data")
for ax in axes:
ax.set_xlabel("$x_1$")
ax.set_ylabel("$x_2$")
plt.tight_layout()
plt.show()
X_batch, y_batch = next(iter(train_loader))
X_test_batch, y_test_batch = next(iter(test_loader))
print("X_batch shape:", X_batch.shape)
print("y_batch shape:", y_batch.shape)
print("X_test_batch shape:", X_test_batch.shape)
print("y_test_batch shape:", y_test_batch.shape)
X_batch shape: torch.Size([400, 2])
y_batch shape: torch.Size([400])
X_test_batch shape: torch.Size([200, 2])
y_test_batch shape: torch.Size([200])
3. 模型、损失与一次更新¶
Logistic 回归的模型就是 X @ a + b。代码中让模型直接输出 logits,再交给 BCEWithLogitsLoss 计算二分类交叉熵。
def predict_logits(X, a, b):
return X @ a + b
a = nn.Parameter(torch.zeros(2))
b = nn.Parameter(torch.zeros(()))
criterion = nn.BCEWithLogitsLoss()
optimizer = torch.optim.SGD([a, b], lr=0.1)
optimizer.zero_grad() # 1. 清零旧梯度
logits = predict_logits(X_batch, a, b) # 2. 前向计算
loss = criterion(logits, y_batch) # 2. 计算损失
loss.backward() # 3. 计算梯度
optimizer.step() # 4. 更新参数
print("loss:", round(loss.item(), 4))
print("gradient of a:", a.grad)
print("updated a:", a.detach())loss: 0.6931
gradient of a: tensor([-1.2169, -1.1474])
updated a: tensor([0.1217, 0.1147])
4. 训练循环¶
下面把同样四步重复很多次。注意:这里 train_loader 每次只给出一个 full-batch,所以每个 epoch 只更新一次参数。
initial_a = torch.tensor([-1.0, -1.0])
initial_b = torch.tensor(0.0)
def compute_accuracy(X, y, a, b):
with torch.no_grad():
probabilities = torch.sigmoid(predict_logits(X, a, b))
predictions = (probabilities >= 0.5).float()
return (predictions == y).float().mean().item()
def train_full_batch(learning_rate, epochs=100):
a = nn.Parameter(initial_a.clone())
b = nn.Parameter(initial_b.clone())
optimizer = torch.optim.SGD([a, b], lr=learning_rate)
with torch.no_grad():
initial_loss = criterion(predict_logits(X_train, a, b), y_train)
train_losses = [initial_loss.item()]
test_accuracies = [compute_accuracy(X_test, y_test, a, b)]
for epoch in range(epochs):
for X_batch, y_batch in train_loader:
optimizer.zero_grad()
loss = criterion(predict_logits(X_batch, a, b), y_batch)
loss.backward()
optimizer.step()
with torch.no_grad():
train_loss = criterion(predict_logits(X_train, a, b), y_train)
train_losses.append(train_loss.item())
test_accuracies.append(compute_accuracy(X_test, y_test, a, b))
return train_losses, test_accuracies5. 比较不同学习率¶
固定数据和初始点,只改变学习率。运行前可以先预测:学习率太小、适中、太大时,训练损失和测试准确率会有什么不同?
learning_rates = [0.02, 0.20, 4.00]
experiments = {}
for lr in learning_rates:
label = f"lr={lr:.2f}"
train_losses, test_accuracies = train_full_batch(learning_rate=lr)
experiments[label] = {"train_loss": train_losses, "test_accuracy": test_accuracies}
print(
label,
"final train loss =",
round(train_losses[-1], 4),
"final test accuracy =",
f"{test_accuracies[-1]:.1%}",
)
fig, axes = plt.subplots(1, 2, figsize=(9, 3))
for label, result in experiments.items():
axes[0].plot(result["train_loss"], label=label)
axes[1].plot(result["test_accuracy"], label=label)
axes[0].set_title("Full-batch training loss")
axes[0].set_xlabel("epoch")
axes[0].set_ylabel("BCE loss")
axes[0].legend()
axes[1].set_title("Test accuracy")
axes[1].set_xlabel("epoch")
axes[1].set_ylabel("accuracy")
axes[1].set_ylim(0, 1.05)
axes[1].legend()
plt.tight_layout()
plt.show()lr=0.02 final train loss = 0.3885 final test accuracy = 87.5%
lr=0.20 final train loss = 0.3875 final test accuracy = 88.0%
lr=4.00 final train loss = 2.5279 final test accuracy = 87.5%
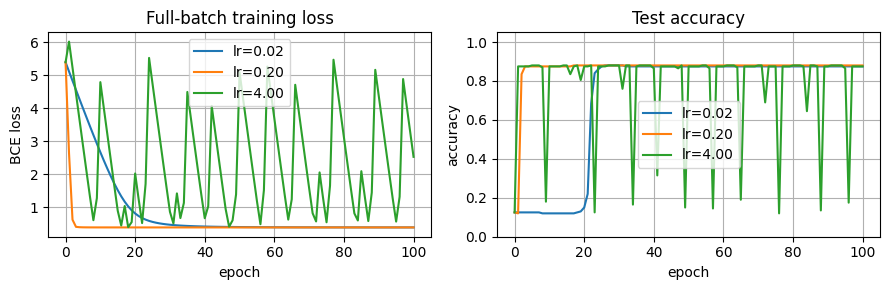
观察问题:
哪个学习率让训练损失下降最快?
哪个学习率的测试准确率最高、最稳定?
如果损失曲线大幅震荡,应该把学习率调大还是调小?
6. 自己动手¶
只修改下面的 learning_rate_try,观察损失曲线如何变化。
learning_rate_try = 0.20
train_losses, test_accuracies = train_full_batch(learning_rate=learning_rate_try)
fig, axes = plt.subplots(1, 2, figsize=(9, 3))
axes[0].plot(train_losses)
axes[0].set_title(f"training loss, lr = {learning_rate_try}")
axes[0].set_xlabel("epoch")
axes[0].set_ylabel("BCE loss")
axes[1].plot(test_accuracies)
axes[1].set_title(f"test accuracy, lr = {learning_rate_try}")
axes[1].set_xlabel("epoch")
axes[1].set_ylabel("accuracy")
axes[1].set_ylim(0, 1.05)
plt.tight_layout()
plt.show()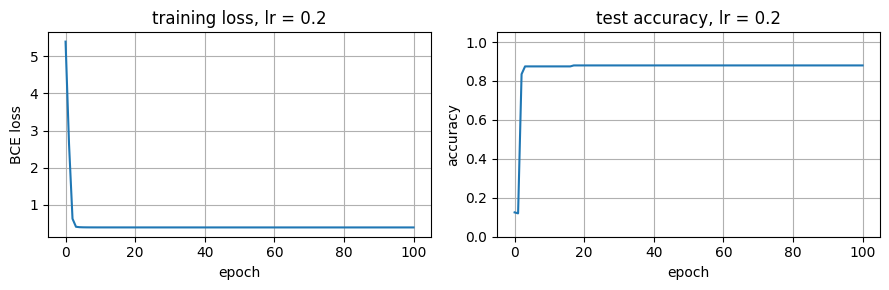
7. 小结¶
本节 notebook 对应讲义中的主线:
TensorDataset和DataLoader把数据组织成 batch;nn.Parameter表示需要训练的参数;BCEWithLogitsLoss计算二分类交叉熵;loss.backward()计算梯度,optimizer.step()更新参数;学习率控制每一步走多远,会影响训练速度、稳定性和测试准确率。
下一节会把 full-batch 改成 mini-batch,由此引出随机梯度法。