4.1 拟合问题
这份 notebook 对应讲义“第4章-应用-部分1”。目标是用几个小实验说明:
不同的残差罚函数会给出不同的拟合结果。
当数据里有野值时,
L^1和 Huber 往往比L^2更鲁棒。当矩阵接近奇异时,正则化可以让解更稳定。
import numpy as np
import matplotlib.pyplot as plt
import cvxpy as cp
np.set_printoptions(precision=3, suppress=True)
plt.rcParams['figure.figsize'] = (6, 3)
plt.rcParams['axes.grid'] = True# Solve a CVXPY problem
def solve_problem(objective, constraints=None):
if constraints is None:
constraints = []
problem = cp.Problem(objective, constraints)
problem.solve()
if problem.status not in {cp.OPTIMAL, cp.OPTIMAL_INACCURATE}:
raise RuntimeError(f'Optimization failed with status: {problem.status}')
return problem
# Summarize a residual vector with a few norms and optional threshold statistics.
def residual_metrics(residual, threshold=None):
metrics = {
'mean|r|': np.mean(np.abs(residual)),
'||r||_2': np.linalg.norm(residual, 2),
'||r||_∞': np.linalg.norm(residual, np.inf),
'max|r|': np.max(np.abs(residual)),
}
if threshold is not None:
metrics[f'prob(|r|<={threshold:g})'] = np.mean(np.abs(residual) <= threshold)
return metrics
# Print the residual summary in a consistent format for comparison.
def print_metrics(name, residual, threshold=None):
metrics = residual_metrics(residual, threshold)
print(name)
for key, value in metrics.items():
print(f' {key:>16s} = {value:.3f}')
# Piecewise Huber penalty: quadratic near 0, linear for large residuals.
def huber_penalty(u, M):
abs_u = np.abs(u)
return np.where(abs_u <= M, abs_u**2, M * (2 * abs_u - M))
# Deadzone penalty ignores residuals inside the tolerance band [-a, a].
def deadzone_penalty(u, a):
return np.maximum(np.abs(u) - a, 0.0)
# Log barrier blows up as |u| approaches a, so it enforces an interior constraint.
def log_barrier_penalty(u, a):
return -a**2 * np.log(1 - (u / a) ** 2)
# Build and solve the fitting model corresponding to the chosen penalty.
def solve_penalty_model(A, b, kind, *, p=8, a=0.5, M=0.6):
n = A.shape[1]
x = cp.Variable(n)
residual = A @ x - b
constraints = []
if kind == 'l2':
objective = cp.Minimize(cp.sum_squares(residual))
elif kind == 'l1':
objective = cp.Minimize(cp.norm(residual, 1))
elif kind == 'lp':
objective = cp.Minimize(cp.sum(cp.power(cp.abs(residual), p)))
elif kind == 'deadzone':
objective = cp.Minimize(cp.sum(cp.pos(cp.abs(residual) - a)))
elif kind == 'log_barrier':
# Stay slightly inside |r| < a to avoid evaluating log at the boundary.
constraints = [cp.abs(residual) <= (1 - 1.0e-4) * a]
objective = cp.Minimize(-a**2 * cp.sum(cp.log(1 - cp.square(residual) / a**2)))
elif kind == 'huber':
objective = cp.Minimize(cp.sum(cp.huber(residual, M)))
else:
raise ValueError('unknown model type')
problem = solve_problem(objective, constraints)
return x.value, A @ x.value - b, problem.value例子1:不同罚函数会带来什么差别?¶
我们构造一个带噪声的线性模型 ,再比较不同罚函数下得到的残差分布。
这里重点观察:
L^2会不会更重地惩罚大残差;L^p(这里取较大的 )是否更倾向于压小最大残差;deadzone 是否允许一部分小残差“无代价”;
log barrier 是否会强迫残差留在给定阈值内。代码里会用一个很小的安全余量,避免数值上贴到边界。
np.random.seed(2)
m = 100
n = 30
noise_level = 0.5
A = np.random.rand(m, n)
x_true = np.random.rand(n)
b = A @ x_true + noise_level * np.random.randn(m)
print('A shape =', A.shape)
print('b shape =', b.shape)A shape = (100, 30)
b shape = (100,)
penalty_specs = {
'L2': {'kind': 'l2'},
'L1': {'kind': 'l1'},
'Lp (p=8)': {'kind': 'lp', 'p': 8},
'Deadzone (a=0.4)': {'kind': 'deadzone', 'a': 0.4},
'Log barrier (a=1.0)': {'kind': 'log_barrier', 'a': 1.0},
'Huber (M=0.6)': {'kind': 'huber', 'M': 0.6},
}
penalty_results = {}
for name, spec in penalty_specs.items():
x_value, residual, objective_value = solve_penalty_model(A, b, **spec)
penalty_results[name] = {
'x': x_value,
'residual': residual,
'objective_value': objective_value,
'spec': spec,
}
for name, result in penalty_results.items():
threshold = result['spec'].get('a')
show_threshold = name.startswith('Deadzone') or name.startswith('Log barrier')
print_metrics(name, result['residual'],\
threshold=threshold if show_threshold else None)
print()
L2
mean|r| = 0.348
||r||_2 = 4.373
||r||_∞ = 1.551
max|r| = 1.551
L1
mean|r| = 0.316
||r||_2 = 4.708
||r||_∞ = 1.762
max|r| = 1.762
Lp (p=8)
mean|r| = 0.440
||r||_2 = 4.996
||r||_∞ = 0.878
max|r| = 0.878
Deadzone (a=0.4)
mean|r| = 0.367
||r||_2 = 4.508
||r||_∞ = 1.749
max|r| = 1.749
prob(|r|<=0.4) = 0.600
Log barrier (a=1.0)
mean|r| = 0.405
||r||_2 = 4.708
||r||_∞ = 0.933
max|r| = 0.933
prob(|r|<=1) = 1.000
Huber (M=0.6)
mean|r| = 0.339
||r||_2 = 4.417
||r||_∞ = 1.823
max|r| = 1.823
u_grid = np.linspace(-2.5, 2.5, 400)
penalty_curves = {
'L2': u_grid**2,
'L1': np.abs(u_grid),
'Lp (p=8)': np.abs(u_grid) ** 8,
'Deadzone (a=0.4)': deadzone_penalty(u_grid, 0.4),
'Log barrier (a=1.0)': log_barrier_penalty(np.linspace(-0.98, 0.98, 400), 1.0),
'Huber (M=0.6)': huber_penalty(u_grid, 0.6),
}
fig, axes = plt.subplots(2, 3, figsize=(12, 6))
for ax, name in zip(axes.flat, penalty_specs):
if name.startswith('Log barrier'):
grid = np.linspace(-0.98, 0.98, 400)
ax.plot(grid, penalty_curves[name], color='red')
ax.set_xlim(-1.1, 1.1)
else:
ax.plot(u_grid, penalty_curves[name], color='red')
ax.set_title(name)
ax.set_xlabel('u')
ax.set_ylabel(r'$\phi(u)$')
plt.tight_layout()
plt.show()
fig, axes = plt.subplots(2, 3, figsize=(12, 6))
for ax, (name, result) in zip(axes.flat, penalty_results.items()):
ax.hist(result['residual'], bins=20, density=True,
alpha=0.75, color='steelblue')
ax.set_title(name)
ax.set_xlabel('residual')
ax.set_ylabel('density')
ax.set_xlim(-2.5, 2.5)
plt.tight_layout()
plt.show()
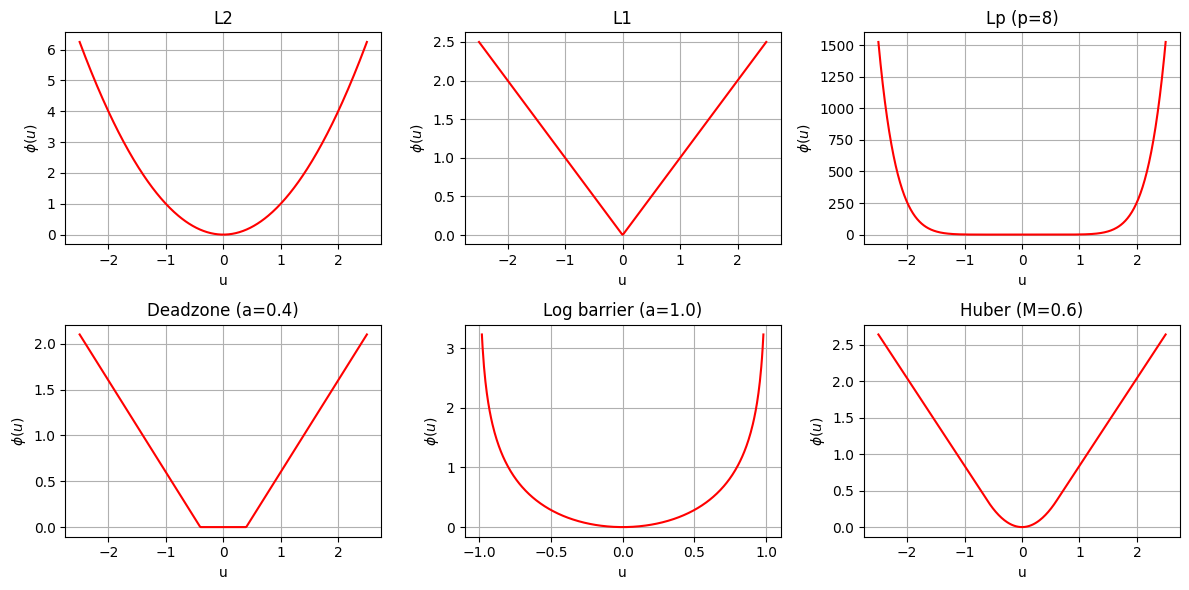
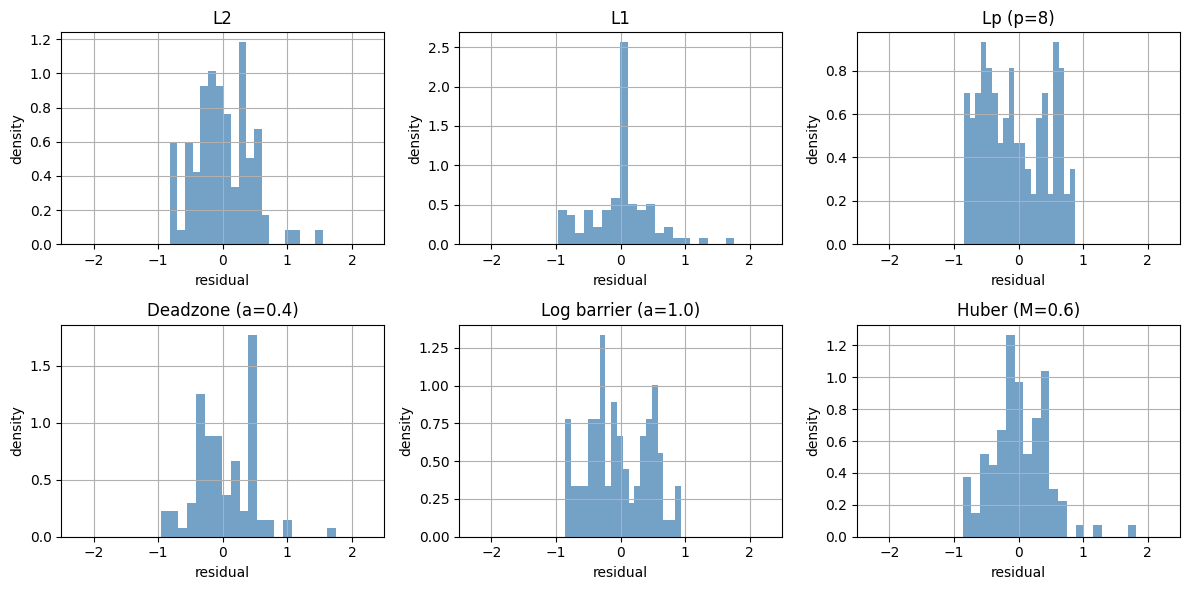
观察
L^2对大残差更敏感。L^p(较大)会更努力压小最大残差。deadzone 的目标是“只惩罚超过阈值的残差”。
log barrier 要求残差必须留在阈值内。这里选 ,因此更容易观察到“超过阈值会被强烈阻止”。
Huber 在小残差区域像
L^2,在大残差区域更像L^1。
例子2:野值与鲁棒性¶
下面构造一维直线拟合问题。大多数数据点都接近真实直线,但有少量点带有很大的异常误差。
我们比较 L^2、L^1 和 Huber:
L^2是否会被野值明显拉偏;L^1和 Huber 是否更接近真实参数。
np.random.seed(1)
m_line = 100
x_data = np.random.randn(m_line, 1)
A_line = np.hstack([x_data, np.ones((m_line, 1))])
beta_true = np.array([1.0, 2.0])
outlier_mask = np.random.rand(m_line) < 0.05
b_line = A_line @ beta_true + 0.2 * np.random.randn(m_line) \
+ 10.0 * np.random.randn(m_line) * outlier_mask
plt.figure(figsize=(6, 3))
plt.scatter(x_data[~outlier_mask], b_line[~outlier_mask], \
alpha=0.4, label='normal points')
plt.scatter(x_data[outlier_mask], b_line[outlier_mask], \
color='red', label='outliers')
plt.legend()
plt.tight_layout()
plt.show()
print('true parameters =', beta_true)
print('number of outliers =', int(outlier_mask.sum()))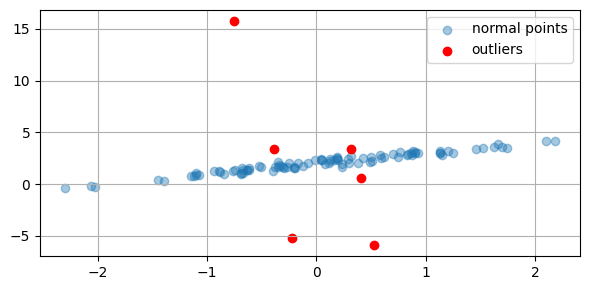
true parameters = [1. 2.]
number of outliers = 6
beta_l2 = cp.Variable(2)
problem_l2 = solve_problem(cp.Minimize(cp.sum_squares(A_line @ beta_l2 - b_line)))
beta_l1 = cp.Variable(2)
problem_l1 = solve_problem(cp.Minimize(cp.norm(A_line @ beta_l1 - b_line, 1)))
beta_huber = cp.Variable(2)
huber_M = 1.0
obj = cp.Minimize(cp.sum(cp.huber(A_line @ beta_huber - b_line, huber_M)))
problem_huber = solve_problem(obj)
robust_results = {
'L2': beta_l2.value,
'L1': beta_l1.value,
'Huber': beta_huber.value,
}
for name, beta in robust_results.items():
parameter_error = np.linalg.norm(beta - beta_true)
clean_residual = A_line[~outlier_mask] @ beta - b_line[~outlier_mask]
print(f'{name}:')
print(f' estimated parameters = [{beta[0]:.4f}, {beta[1]:.4f}]')
print(f' parameter error = {parameter_error:.4f}')
print(f' clean mean|r| = {np.mean(np.abs(clean_residual)):.4f}')
print()L2:
estimated parameters = [0.8260, 2.0284]
parameter error = 0.1763
clean mean|r| = 0.2253
L1:
estimated parameters = [1.0030, 2.0232]
parameter error = 0.0234
clean mean|r| = 0.1697
Huber:
estimated parameters = [0.9971, 2.0168]
parameter error = 0.0170
clean mean|r| = 0.1702
观察¶
这组数据里只有少量野值,但 L^2 往往会明显受它们影响。相比之下,L^1 和 Huber 更接近真实直线,因此常被称为更鲁棒的选择。
例子3:正则化与稳定性¶
最后看一个与讲义后半部分一致的例子。
我们构造一个接近奇异的矩阵 。这时,即使 只发生很小的扰动,最优解也可能变化很大。我们比较:
无正则的最小二乘;
加上 的正则化。
这里要特别注意:正则化通常不是让拟合误差最小,而是用一点偏差换取更稳定的解。
eps = 1.0e-3
delta = 1.0e-2
A_near = np.array([[1.0, 1.0], [1.0 + eps, 1.0]])
x_exact = np.array([1.0, 1.0])
b_clean = A_near @ x_exact
b_perturbed = b_clean + np.array([1.0e-2, 0.0])
print('A =')
print(A_near)
print('clean b =', b_clean)
print('perturbed b =', b_perturbed)
A =
[[1. 1. ]
[1.001 1. ]]
clean b = [2. 2.001]
perturbed b = [2.01 2.001]
def solve_least_squares_reference(A, b):
return np.linalg.solve(A.T @ A, A.T @ b)
def solve_regularized_reference(A, b, delta):
n = A.shape[1]
return np.linalg.solve(A.T @ A + delta * np.eye(n), A.T @ b)
x_ls_clean = solve_least_squares_reference(A_near, b_clean)
x_ls_perturbed = solve_least_squares_reference(A_near, b_perturbed)
x_regularized_clean = solve_regularized_reference(A_near, b_clean, delta)
x_regularized_perturbed = solve_regularized_reference(A_near, b_perturbed, delta)
residual_ls_clean = np.linalg.norm(A_near @ x_ls_clean - b_clean)
residual_ls_perturbed = np.linalg.norm(A_near @ x_ls_perturbed - b_perturbed)
residual_regularized_clean = np.linalg.norm(A_near @ x_regularized_clean - b_clean)
residual_regularized_perturbed = np.linalg.norm(A_near @ x_regularized_perturbed - b_perturbed)
print('Without regularization:')
print(' x(clean b) =', x_ls_clean)
print(' x(perturbed b) =', x_ls_perturbed)
print(f' change in x = {np.linalg.norm(x_ls_perturbed - x_ls_clean):.3f}')
print(f' ||Ax-b|| on clean = {residual_ls_clean:.3e}')
print(f' ||Ax-b|| perturbed = {residual_ls_perturbed:.3e}')
print()
print('With regularization:')
print(' x(clean b) =', x_regularized_clean)
print(' x(perturbed b) =', x_regularized_perturbed)
print(f' change in x = {np.linalg.norm(x_regularized_perturbed - x_regularized_clean):.3f}')
print(f' ||Ax-b|| on clean = {residual_regularized_clean:.3e}')
print(f' ||Ax-b|| perturbed = {residual_regularized_perturbed:.3e}')Without regularization:
x(clean b) = [1. 1.]
x(perturbed b) = [-9. 11.01]
change in x = 14.149
||Ax-b|| on clean = 3.140e-13
||Ax-b|| perturbed = 3.272e-12
With regularization:
x(clean b) = [0.998 0.997]
x(perturbed b) = [1. 1.]
change in x = 0.004
||Ax-b|| on clean = 7.052e-03
||Ax-b|| perturbed = 1.000e-02
小结¶
这份 notebook 对应讲义中的三个核心结论:
罚函数的形状会显著影响拟合结果。
当数据里有野值时,
L^1和 Huber 往往比L^2更鲁棒。当矩阵接近奇异时,正则化可以降低解对数据扰动的敏感性。